無需標注數據 云從科技及聯合研究團隊提出一種視覺模型自監督學習方法
游戲《光環》中的
人工智能科塔娜說過一句話,
“我是他的盾牌,我是他的利刃;我深知他,連同他的過去和未來”。
作為“六感”之首的視覺,占據了人類吸收外部信息的70%以上。如果說人工智能的遠景是打造一個具有大腦、神經、軀干與四肢的機器人,那么,硬件基礎是軀干、四肢,更重要的是,要使得機器人能看會想,能聽會說,就要搭建神經和大腦。
訓練視覺模型的目標是教會AI看見和理解現實世界,其中,點云視頻理解對于智能體與世界的交互至關重要。
近日,國際計算機視覺頂會CVPR 2023在加拿大溫哥華舉行。作為國際計算機視覺與模式識別領域的三大頂級會議之一,CVPR備受關注。云從科技及聯合研究團隊的論文《PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos》(基于掩碼預測的點云視頻自監督學習)成功入選。

01
簡介
從靜態點云中解析現實世界已經取得了巨大的成就。最近,對點云視頻的理解也越來越受關注。與此同時,自監督學習可以從未標注的數據中提取高質量的表征,這將為標注成本高昂的點云視頻理解任務帶來幫助。
因此,我們探索了以自監督的方式從點云視頻中學習表征的方法。盡管基于對比學習和掩碼預測的自監督學習范式已經在圖像和靜態點云領域顯示出了強大的有效性,但是將這些方法直接擴展到點云視頻上仍存在諸多挑戰。
在本文中,我們提出了PointCMP,一種用于點云視頻自監督學習的對比掩碼預測框架。PointCMP采用雙分支結構,同步學習點云視頻的局部和全局時空信息。在此之上,我們提出了一個基于互相似度的增強模塊,以實現基于特征的樣本生成。
通過計算各局部表征與該樣本全局語義之間的相似度,我們可以找到那些與語義高度相關的關鍵部分。將這些關鍵部分掩蔽可以提升自監督預測任務的挑戰性,以促使模型學習更有效的表征。與此同時,我們也嘗試擦除關鍵的特征通道,從而針對性的生成難負例用于全局對比學習。
02
方法
我們的PointCMP架構如圖1所示。給定一個點云視頻,首先將其均勻地分成多個視頻片段。然后,將這些片段送入編碼器得到局部Token以及具有全局語義的全局Token。接下來,將它們傳遞給基于互相似度的增強模塊。
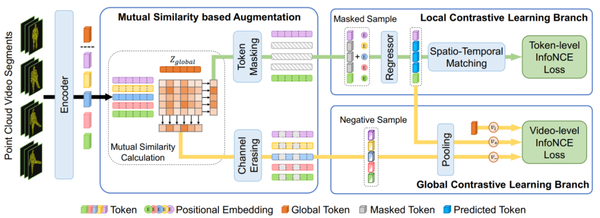
圖1 PointCMP的架構示意圖
從直覺上來說,當與全局Token具有較高相似度的局部Token可見時,預測任務會變得更容易。因此,我們掩蔽掉這些具有高相似度的局部Token以生成有難度的掩碼樣本。我們選擇相似度高的Token作為關鍵Token。各局部Token所覆蓋的點云通常有重疊,而視頻片段之間有一定的信息隔離。
因此,我們選擇包含最多個關鍵Token的視頻片段,并將此片段下聚合而成的所有局部Token都掩蔽掉。此外,我們將具有高相關度的特征通道視為主通道,并將它們擦除以生成難負樣本。直觀上來說,擦除掉這些重要的主成分特征后勢必會與原始樣本形成一個負樣本對。
我們將帶有掩碼的Token序列與位置編碼相加后輸給一個回歸器,來預測被掩碼處的表征。被預測的表征與編碼器得到的相對應的原始表征組成正樣本對,而與其余的組成負樣本對。我們使用InfoNCE損失來完成此局部對比學習分支。
與此同時,我們還為樣本的全局表征構建了全局對比學習分支。由回歸器重新補全的Token序列經過池化層得到新的全局表征,并與原始全局表征構成正樣本對。
擦除主特征通道后的Token序列經過池化層得到全局難負例。并且,同一批次內的其他視頻的全局表征也作為當前樣本的負樣本。我們同樣使用InfoNCE損失來完成此全局對比學習分支。
03
實驗
首先,我們對預訓練后的編碼器進行微調,來評估PointCMP學習到的表征。我們將MSRAction-3D數據集同時用于預訓練和端到端微調。當使用PSTNet作為編碼器時,相對于基線,PointCMP預訓練帶來了顯著的精度改進。
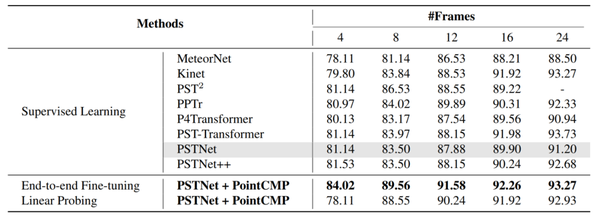
表1 MSRAction-3D數據集上的驗證結果
如表1所示,在使用8 幀時,行為識別的精度從83.50%提高到89.56%。這表明,PointCMP預訓練可以以自監督的方式從點云視頻中學習到有益的知識,這有助于在微調后獲得更高的精度。
然后,我們通過線性實驗來驗證PointCMP預訓練所學到的表征的有效性。同樣的,MSRAction-3D數據集被用于預訓練和線性測試。預訓練的編碼器被凍結,并添加一個額外的線性分類器用于監督訓練。我們的方法在大多數幀數設置下都超過了基線。這證明了PointCMP預訓練讓模型學習到了高質量的表征。

表2 NTU-RGBD (Cross-Subject) 數據集上的驗證結果
此外,我們還在NTU-RGBD數據集上做了半監督實驗,即在自監督預訓練后用一部分有標注的數據微調模型。從表2的結果來看,當我們使用PSTNet作為編碼器時,只用50%的標注數據微調模型就可以接近全監督的基線精度。這表明PointCMP預訓練可以在無標注數據中挖掘數據自身所蘊含的知識,這不僅可以節約人力成本還可以將預訓練模型作為初始化從而進一步提升模型的性能。

圖2 高相似度局部Token及其鄰域點(綠色)的可視化結果
我們在圖2中進一步可視化了與全局Token具有高度相似性的關鍵局部Token及其鄰域點。正如我們所看到的,與運動的關鍵身體部位相對應的點被突出顯示。這與我們的直覺是一致的。通過掩蔽這些關鍵區域,鼓勵編碼器利用更多上下文進行掩碼預測,以此學習更高質量的表征。
總結展望
自監督學習的優勢主要是利用輔助任務從無標注數據中挖掘自身的監督信息。相比于利用特定任務的標注作為監督信息訓練,這不僅可以節省標注成本,還可以使模型學習到更泛化的知識和對多種下游任務有價值的表征。在數據為王的時代,此特點也使得大家充分相信自監督學習才是人工智能的發展方向。
另一方面,點云視頻含有豐富的動態視覺信息,可以幫助智能體充分了解這個實時變化的3D世界。且相比于傳統視頻以紋理信息為主,點云視頻涵蓋更精確的幾何信息和位置坐標。
所以,點云視頻可以為低能見度環境中的動作識別等任務提供保障。由此可見,點云視頻理解對于人工智能系統與世界交互非常重要。在海量數據之上,借助自監督技術推動點云視頻理解,也許會幫助我們打造一個能想會說、能聽會看的AI。
您可能感興趣
-
 2023-06-27
2023-06-27云從科技及聯合研究團隊的論文《PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos》(基于掩碼預測的點云視頻自監督學習)成功入選。
-
 2023-06-27
2023-06-27云從科技與上海交通大學聯合研究團隊的《基于擴散模型的音頻驅動說話人生成》成功入選會議論文,并于大會進行現場宣講,獲得多方高度關注。
-
 2025-04-01
2025-04-01近日,云從科技與重慶大學大數據與軟件學院聯合研發的編程智能體——CoSEFA(Code SEcurity and Fix Agent)被軟件工程領域頂尖會議ACM SIGSOFT軟件工程基礎國際會議(FSE 2025)正式錄用。







