云從科技聯(lián)合上海交大發(fā)布AIGC跨模態(tài)數(shù)字人技術(shù)
近日,國(guó)際語(yǔ)音及信號(hào)處理領(lǐng)域頂級(jí)會(huì)議ICASSP2023在希臘成功舉辦。大會(huì)邀請(qǐng)了全球范圍內(nèi)各大研究機(jī)構(gòu)、專家學(xué)者以及等谷歌、蘋果華為、Meta AI、等知名企業(yè)近4000人共襄盛會(huì),探討技術(shù)、產(chǎn)業(yè)發(fā)展趨勢(shì),交流最新成果。

云從科技與上海交通大學(xué)聯(lián)合研究團(tuán)隊(duì)的《基于擴(kuò)散模型的音頻驅(qū)動(dòng)說(shuō)話人生成》成功入選會(huì)議論文,并于大會(huì)進(jìn)行現(xiàn)場(chǎng)宣講,獲得多方高度關(guān)注。
ICASSP(International Conference on Acoustics, Speech and Signal Processing)是語(yǔ)音、聲學(xué)領(lǐng)域的頂級(jí)國(guó)際會(huì)議之一, ICASSP學(xué)術(shù)會(huì)議上展示的研究成果,被認(rèn)為代表著聲學(xué)、語(yǔ)音領(lǐng)域的前沿水平與未來(lái)發(fā)展方向。
本次入選論文,圍繞“基于音頻驅(qū)動(dòng)的說(shuō)話人視頻生成”這一視覺(jué)-音頻的跨模態(tài)任務(wù),將語(yǔ)音與視覺(jué)技術(shù)結(jié)合,提出的方法能夠根據(jù)輸入的語(yǔ)音片段技術(shù),生成自然的頭部動(dòng)作,準(zhǔn)確的唇部動(dòng)作和高質(zhì)量的面部表情說(shuō)話視頻。該項(xiàng)成果在多個(gè)數(shù)據(jù)集上,都取得了優(yōu)于過(guò)去研究的表現(xiàn)。
此外,在實(shí)戰(zhàn)場(chǎng)景中,隨著現(xiàn)實(shí)生活中對(duì)于數(shù)字人引用的愈來(lái)愈廣泛,實(shí)現(xiàn)用音頻驅(qū)動(dòng)的生成與輸入音頻同步的說(shuō)話人臉視頻的需求也越來(lái)越大。本項(xiàng)成果基于擴(kuò)散模型的跨模態(tài)說(shuō)話人生成技術(shù),可以推廣到廣泛的應(yīng)用場(chǎng)景,例如虛擬新聞廣播,虛擬演講和視頻會(huì)議等等。
論文地址:https://ieeexplore.ieee.org/document/10094937/
01
簡(jiǎn)介
基于音頻驅(qū)動(dòng)的說(shuō)話人視頻生成任務(wù)(Audio-driven Talking face Video Generation):該任務(wù)是根據(jù)目標(biāo)人物的一張照片和任意一段語(yǔ)音音頻,生成與音頻同步的目標(biāo)人物說(shuō)話的視頻。由于其生成的說(shuō)話人更自然、準(zhǔn)確的唇形運(yùn)動(dòng)和保真度更高的頭部姿態(tài)、面部表情,該任務(wù)廣泛應(yīng)用于如數(shù)字人、虛擬視頻會(huì)議和人機(jī)交互等領(lǐng)域,作為視覺(jué)-音頻的跨模態(tài)任務(wù),基于音頻驅(qū)動(dòng)的說(shuō)話人視頻生成也受到了越來(lái)越多的關(guān)注。
為了構(gòu)建音頻信號(hào)到面部形變的映射,現(xiàn)有方法引入了中間人臉表征,包括2D關(guān)鍵點(diǎn)或者3D morphable face model (3DMM),盡管這些方法在音頻驅(qū)動(dòng)的面部重演任務(wù)上取得了良好的視覺(jué)質(zhì)量,但由于中間人臉表征造成的信息損失,可能會(huì)導(dǎo)致原始音頻信號(hào)和學(xué)習(xí)到的人臉變形之間的語(yǔ)義不匹配。
此外基于GAN的方法訓(xùn)練不穩(wěn)定,很容易陷入模型崩塌,往往它們只能生成具有固定分辨率的圖像。針對(duì)以上問(wèn)題,AD-Nerf引入了神經(jīng)輻射場(chǎng),將音頻信號(hào)直接輸入動(dòng)態(tài)輻射場(chǎng)的隱式函數(shù),最后渲染得到逼真的合成視頻。但是基于神經(jīng)輻射場(chǎng)的方法計(jì)算量大導(dǎo)致訓(xùn)練耗時(shí)長(zhǎng),算力要求高。
并且這些工作大多忽略了個(gè)性化的人臉屬性,無(wú)法準(zhǔn)確的將音頻和唇部運(yùn)動(dòng)進(jìn)行同步。因此本文的研究者們提出了本方法,通過(guò)借助去噪擴(kuò)散模型來(lái)高效地優(yōu)化人臉各部分個(gè)性化屬性特征,進(jìn)而合成高保真度的高清晰視頻。
02
方法
該方法首先基于一個(gè)關(guān)鍵的直覺(jué):唇部運(yùn)動(dòng)與語(yǔ)音信號(hào)高度相關(guān),而個(gè)性化信息,如頭部姿勢(shì)和眨眼,與音頻的關(guān)聯(lián)較弱且因人而異。受到最近擴(kuò)散模型在高質(zhì)量的圖像以及視頻生成方面已經(jīng)取得了快速進(jìn)展的啟發(fā),因此研究者們基于擴(kuò)散模型重新構(gòu)造音頻驅(qū)動(dòng)面部重演的新框架,本方法來(lái)優(yōu)化說(shuō)話人臉視頻的生成質(zhì)量和真實(shí)度。
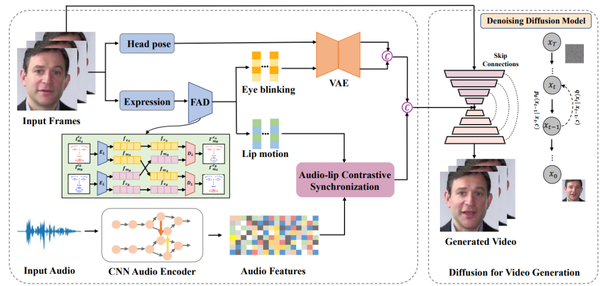
Difface一共包含四大部分:(1)人臉屬性解耦;(2)唇-音對(duì)比同步;(3)動(dòng)態(tài)連續(xù)性屬性信息建模;(4)基于去噪擴(kuò)散模型的說(shuō)話人生成人臉屬性解耦部分中,研究者采用3DMM提取源身份圖像的頭部姿態(tài)和表情系數(shù),然后借鑒之前DFA-nerf的工作采用全連接的自編碼器從表情參數(shù)解耦得到唇部運(yùn)動(dòng)和眨眼動(dòng)作信息。
唇-音對(duì)比同步模塊中,研究者通過(guò)引入自監(jiān)督跨模態(tài)對(duì)比學(xué)習(xí)策略來(lái)部署一個(gè)確定性模型來(lái)同步音頻和唇部運(yùn)動(dòng)的特征。
動(dòng)態(tài)連續(xù)性屬性信息建模模塊中,由于頭部姿勢(shì)和眨眼等個(gè)性化人臉屬性是隨機(jī)的和具有一定概率性的,因此為了對(duì)人臉屬性的概率分布進(jìn)行建模并生成長(zhǎng)時(shí)間序列,研究者提出采用了基于transformer的變分自動(dòng)編碼器(VAE)的概率模型,一是VAE可以用于平滑離散的屬性信息并映射為高斯分布,二是利用Transformer的注意力機(jī)制充分學(xué)習(xí)時(shí)間序列的幀間長(zhǎng)時(shí)依賴性。
基于去噪擴(kuò)散模型的說(shuō)話人生成模塊中,研究者生成的個(gè)性化人臉屬性序列與同步的音頻嵌入相連接作為擴(kuò)散模型的輸入條件。然后利用條件去噪擴(kuò)散概率模型(DDPM)將這些驅(qū)動(dòng)條件以及源人臉作為輸入,通過(guò)擴(kuò)散生成的方式生成最終的高分辨率說(shuō)話人視頻。這些個(gè)性化人臉屬性序列與同步的音頻嵌入用來(lái)豐富擴(kuò)散模型,以保持生成圖像序列的一致性。
03
實(shí)驗(yàn)結(jié)果
研究者們通過(guò)實(shí)驗(yàn)驗(yàn)證了本方法對(duì)于基于音頻驅(qū)動(dòng)的說(shuō)話人視頻生成任務(wù)的優(yōu)越性能。
? 定量比較實(shí)驗(yàn)
研究者將本方法與現(xiàn)有音頻驅(qū)動(dòng)的人臉視頻生成方法通過(guò)定量化分析實(shí)驗(yàn)進(jìn)行比較,采用了峰值信噪比(PSNR), 結(jié)構(gòu)相似度(SSIM),人臉關(guān)鍵點(diǎn)運(yùn)動(dòng)偏移(LMD),視聽(tīng)同步置信度(Sync)等多個(gè)客觀的評(píng)估指標(biāo),具體信息如表1所示。
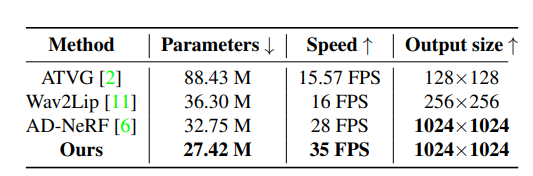
本文所提出的擴(kuò)散生成框架在所有的性能指標(biāo)上都優(yōu)于其他方法,其中PSNR和SSIM驗(yàn)證了人臉屬性解耦方案能夠更好地捕捉說(shuō)話人的頭部姿態(tài)、眨眼等個(gè)性化信息。而本方法的LMD分?jǐn)?shù)意味著本方法的唇音一致性更強(qiáng)。此外,受益于輸入音頻和唇部運(yùn)動(dòng)的跨模態(tài)對(duì)比學(xué)習(xí),本方法在Sync指標(biāo)上大幅超越其他方法。
?定性比較實(shí)驗(yàn)
研究者將本方法與現(xiàn)有音頻驅(qū)動(dòng)的人臉視頻生成方法進(jìn)行比較。通過(guò)個(gè)性化屬性的學(xué)習(xí)以及擴(kuò)散模型的優(yōu)化,我們的方法生成具有個(gè)性化的頭部運(yùn)動(dòng),更加逼真眨眼信息,唇-音同步性能更好的人臉視頻。
? 模型中每個(gè)模塊帶來(lái)的效益
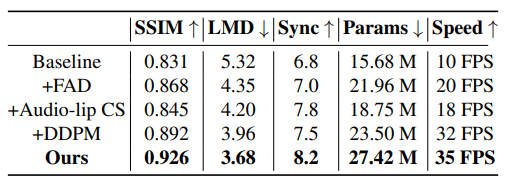
為了突顯出模型中每個(gè)模塊的重要性,研究者們做了消融實(shí)驗(yàn),如表2所示,當(dāng)添加DDPM模塊之后,在推理速度和視覺(jué)質(zhì)量方面相比于其他模塊的提升是最大的,其次,受益于解耦的人臉屬性信息以及VAE的屬性平滑以及動(dòng)態(tài)連續(xù)性建模的作用,說(shuō)話人人臉的自然度得到了提高。此外,唇音對(duì)比學(xué)習(xí)的模塊通過(guò)自監(jiān)督的方式顯著提高了唇部運(yùn)動(dòng)和與輸入音頻的同步質(zhì)量。
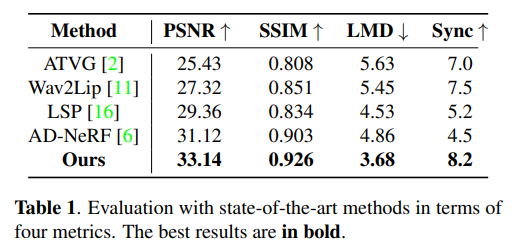
? 模型的效率
研究者們還展示了模型的可訓(xùn)練參數(shù)量,推理速度以及輸出的分辨率大小,并和之前的SOTA模型進(jìn)行了對(duì)比,由于使用去噪擴(kuò)散概率模型,該模型利用變分方法而不是對(duì)抗性訓(xùn)練,并且不需要部署多個(gè)鑒別器,因此極大緩解了訓(xùn)練時(shí)模型容易陷入模型坍塌的問(wèn)題,并且采用了較短的時(shí)間步長(zhǎng),推理速度大大提高,效率得到了提升。
04
結(jié)論
針對(duì)基于音頻驅(qū)動(dòng)的高保真度說(shuō)話人視頻生成這個(gè)任務(wù),云從-上交的聯(lián)合研究團(tuán)隊(duì)提出了,基于擴(kuò)散框架的音頻驅(qū)動(dòng)說(shuō)話人視頻生成方法,只需要一幀或幾幀身份圖像以及輸入語(yǔ)音音頻,即合成一個(gè)高保真度的人臉視頻,實(shí)現(xiàn)了最先進(jìn)的合成視頻視覺(jué)質(zhì)量。此外利用了跨模態(tài)唇音對(duì)比學(xué)習(xí)的方法,從而提升了唇部和音頻的一致性,在公開(kāi)數(shù)據(jù)集上取得了SOTA表現(xiàn)。
您可能感興趣
-
 2022-12-26
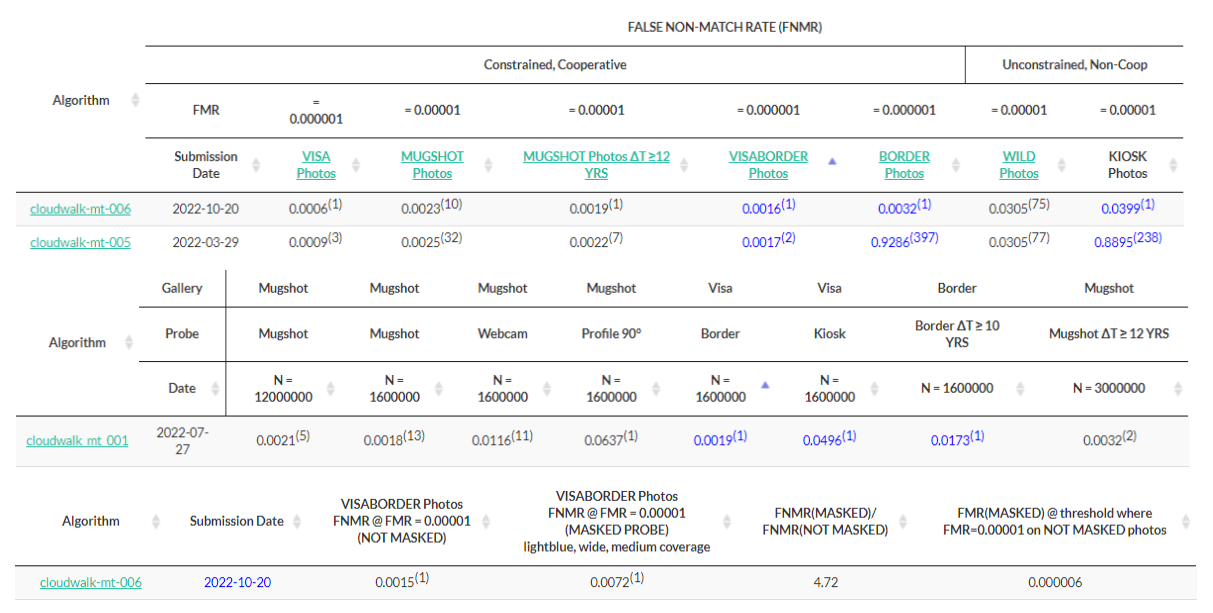
2022-12-26全球權(quán)威人臉識(shí)別算法測(cè)試(NIST-FRVT)發(fā)布最新榜單,云從收獲三個(gè)第一
-
 2023-07-19
2023-07-19云從科技在視覺(jué)大模型上取得重要進(jìn)展,行人基礎(chǔ)大模型在PA-100K、RAP V2、PETA、HICO-DET四個(gè)數(shù)據(jù)集上從阿里巴巴、日立等多家知名高校、企業(yè)與研究機(jī)構(gòu)脫穎而出,刷新了世界紀(jì)錄。
-
 2023-06-27
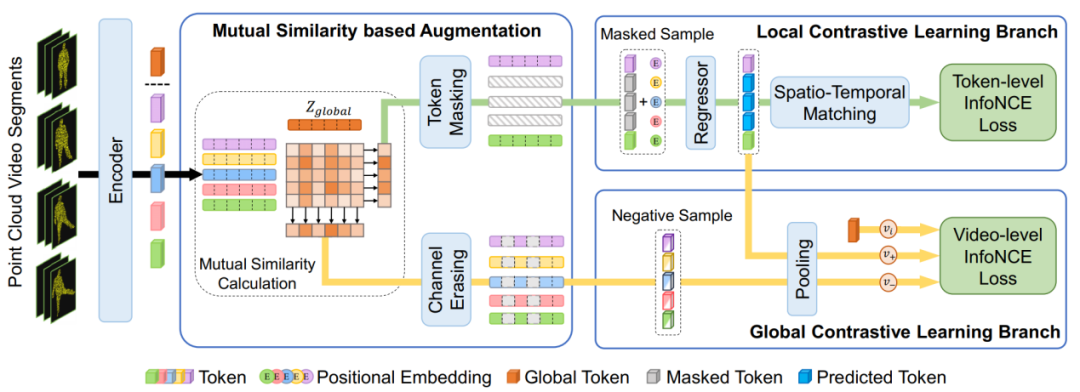
2023-06-27云從科技及聯(lián)合研究團(tuán)隊(duì)的論文《PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos》(基于掩碼預(yù)測(cè)的點(diǎn)云視頻自監(jiān)督學(xué)習(xí))成功入選。







